每隔一段时间,市场上总会出现类似的宣称:"这个策略过去三年胜率高达 82%。"话说到这里,听者的心跳会加快半拍——82%,远胜翻硬币,甚至超过许多职业赌场的庄家优势。这种宣称背后的逻辑链条也显得顺畅:胜率高,意味着大多数时候都是对的;大多数时候都对,意味着账户增长;账户增长,意味着财富积累。
这个推理在直觉上无懈可击。但它在结构上是错的。
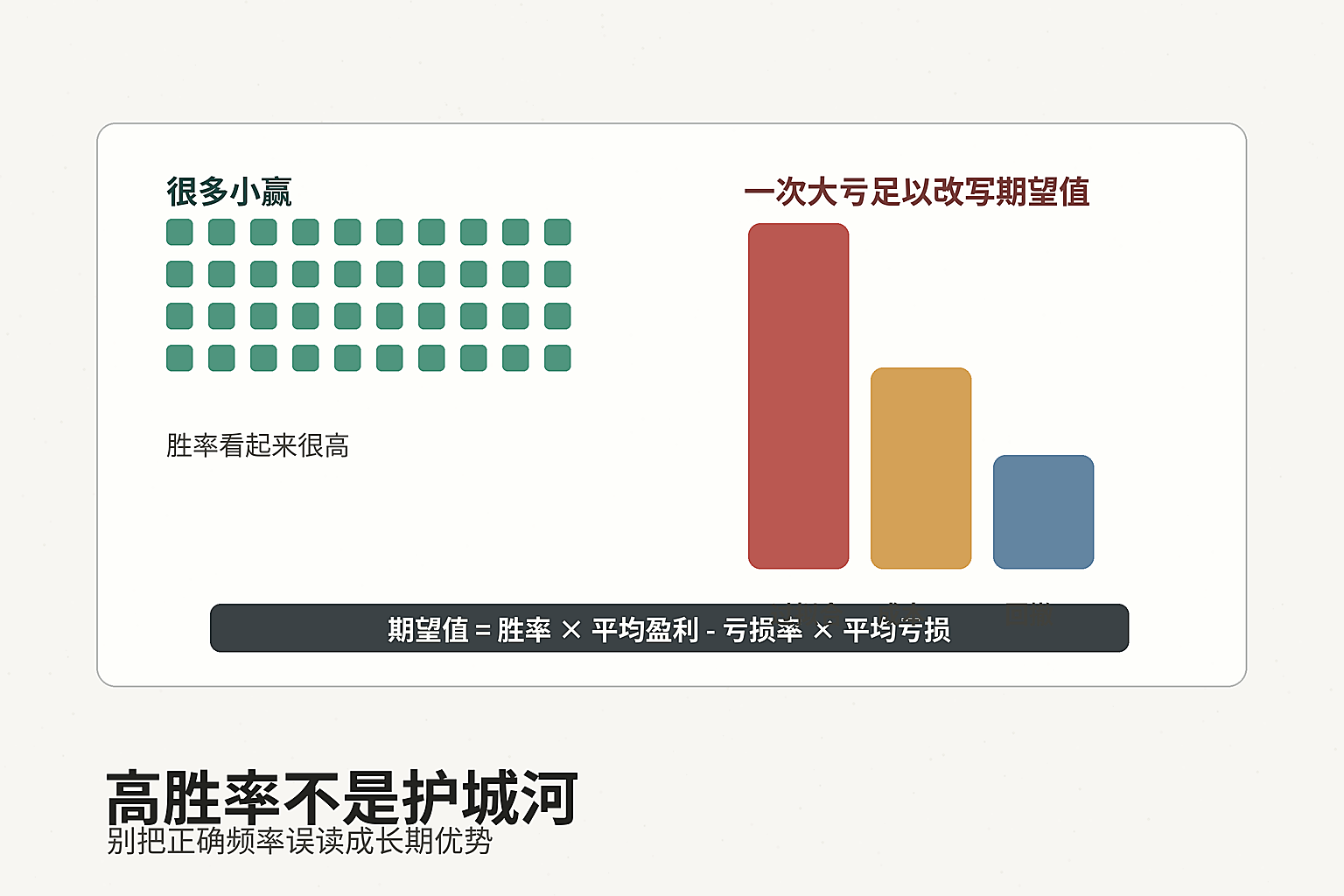
高胜率本身——脱离盈亏比、脱离样本质量、脱离市场环境——不构成任何意义上的竞争优势。它不是护城河,甚至有可能是一张精心设计的陷阱,诱使人在错误的地基上构筑整个投资体系。
本文以一次假设性的 A 股信号回测案例为反面教材,并非讨论任何具体的买卖操作。文中所有数字、情境均属虚构,仅用于方法论的教学说明。
一、胜率的诱惑:为什么"八成准确"让人上瘾
人类大脑对"正确频率"异常敏感。心理学研究表明,频繁的小奖励会激活与多巴胺相关的神经回路——赌场里的老虎机正是这一原理的工业级应用。在投资语境中,胜率扮演了类似角色:每一次"预测正确"都是一次正向刺激,让持有者对这套系统的信念越来越深。
这不是理性判断,而是条件反射。
行为金融学的研究者长期关注一个现象:投资者在评估策略时,对胜率的重视程度系统性地高于对盈亏比的关注。赌两局,各赌 100 元,第一局九成概率赢 10 元,第二局三成概率赢 50 元——许多人会本能地倾向于前者,尽管后者的期望值(15 元)高于前者(9 元 - 1 元 = 8 元(考虑一成亏损时损失 100 元)),期望值差距更为悬殊。
胜率的另一重吸引力来自"社会证明"(social proof)。一个人向朋友展示策略时,说"这个方法十次有八次是对的"比解释"这个方法的期望值在扣除交易成本后为正"要简洁得多,也直观得多。前者可以在饭桌上三秒钟内完成传播;后者需要一块白板和二十分钟。简洁的表达在社会传播中更有优势,这恰恰让胜率成为营销利器——无论它是否揭示了策略的真实价值。
二、胜率 vs. 期望值:九成准确如何摧毁资本
让我们从第一个最基本的错误出发:把胜率等同于盈利能力。
考虑一个假设情境:某 A 股量化信号在 2018 年至 2022 年的历史回测中,触发 200 次,其中 180 次收益为正,平均每次盈利为 2%;20 次亏损,平均每次亏损为 18%。
胜率:180 / 200 = 90%。
期望值:90% × 2% + 10% × (-18%) = 1.8% - 1.8% = 0%。
这个策略在手续费和滑点之前,期望值恰好为零——一个完美的对冲。加入现实中的交易摩擦,期望值变为负数。投资者获得了漂亮的胜率统计,然后亏钱离场。
这不是极端案例。它是胜率崇拜的标准结果。一个擅长"小赢大亏"结构的策略,可以轻易将胜率维持在 85% 以上,同时在足够长的周期内归还所有利润。这类策略在期权卖出(naked put/call writing)领域尤为常见:绝大多数月份均收取权利金,偶尔的黑天鹅事件一次性吞噬全年甚至数年的积累。
结论:胜率必须与盈亏比(payoff ratio)一同考察。一个胜率 60% 、盈亏比 3:1 的策略,其期望值远优于一个胜率 90%、盈亏比 0.2:1 的策略。前者每 10 次交易期望获利 6 × 1 - 4 × 1/3 ≈ 4.7 个单位;后者每 10 次交易期望获利 9 × 0.2 - 1 × 1 = 0.8 个单位。差距不是略微,而是数量级。
三、凯利公式:最优仓位取决于两个参数,缺一不可
1956 年,贝尔实验室的数学家约翰·凯利(John Kelly Jr.)在研究信息噪声时,推导出了一个控制赌注规模的公式,后来被广泛应用于投资领域。他的原始论文 "A New Interpretation of Information Rate" 至今仍是资金管理领域的基础文献。凯利公式的简化版本如下:
f = W - (1-W) / R
其中,f 为应投入资本的比例,W 为单次交易的胜率,R 为盈亏比(平均盈利 / 平均亏损)。
将上述两个例子代入:
| 策略 | 胜率 W | 盈亏比 R | 凯利最优仓位 f |
|---|---|---|---|
| 策略 A(高胜率低盈亏比) | 90% | 0.11 | 90% - 10% / 0.11 ≈ -0.9(不应下注) |
| 策略 B(中胜率高盈亏比) | 60% | 3.0 | 60% - 40% / 3 ≈ 47% |
策略 A 在凯利框架下的最优仓位为负值——这在数学上的含义是:若可以做空这个策略,应当做空。正向持有的期望值为负。
这个计算结果并不神秘。它只是把胜率与盈亏比的乘积还原为真实的期望值,然后告诉你:当期望值为零或负时,无论胜率多高,正确的仓位都是零。胜率是一个输入变量,不是结论。
凯利公式在实践中还有另一重警示意义。许多交易者使用"半凯利"(Half-Kelly)甚至"四分之一凯利"来降低波动——这是基于"凯利全仓"在实际中方差过大的考量,也是基于对模型误差的承认。即使一个策略在历史上期望值为正,凯利全仓仍然可能在参数估计误差中遭受严重回撤。这个保守原则背后隐含的哲学是:对自己的模型保持怀疑,是比盲目执行更成熟的态度。
四、生存者偏差:只有幸存的信号才看起来美好
现在,回到那个"假设性的"高胜率 A 股信号。
假设某分析师在 2018 年对 A 股全市场约 3000 只股票中,测试了 50 种不同的技术信号组合,寻找在当年市场环境下有效的模式。经过筛选,他找到了 3 种在 2018 年和 2019 年均表现优异的信号——胜率分别为 78%、81% 和 84%。他选择了 84% 的那个,并开始记录。
问题在于,这 3 种信号是从 50 种候选中挑选出来的。被丢弃的 47 种,我们再也看不到它们的记录。它们消失在测试过程中,只留下"幸存者"供展示。
这就是生存者偏差(survivorship bias)的运作机制。
在统计学中,当我们只能观察到成功样本时,对总体的估计会系统性地偏高。这个效应在回测领域尤为严重,因为它几乎是不可避免的:分析师天然会展示有效的,并沉默地放弃无效的。没有人写文章介绍"我测试了五十种方法,全部失败"。
更隐蔽的生存者偏差来自市场本身。在 A 股历史数据库中,退市的公司通常不再出现在标准数据接口中,或者即便出现也未必被自动纳入回测范围。一个在 2015 年至 2019 年间表现优异的"困境反转"信号,背后可能有一大批真正走向退市的公司被默默排除在外。留在数据库中的,是那些活下来的;死去的,不在样本里。
美国学者克里斯托弗·杰拉赫(Christopher Geczy)等人在研究共同基金历史时发现,若将退市基金纳入统计,行业平均回报率会系统性地降低 1-2 个百分点。这一效应在个股层面同样存在,且在新兴市场中往往更为显著。
五、过拟合:参数越多,样本外越惨
生存者偏差解决了"展示哪些结果"的问题。过拟合(overfitting)则是另一回事:即使诚实地展示全部测试,这个结果本身也可能毫无意义。
假设那个 84% 胜率的信号,最终被定义为以下条件的组合:
- 股票的 20 日换手率处于近一年的前 15%;
- 当日 RSI 在 42 至 58 之间;
- 近 5 日 MACD 柱状图连续收缩;
- 股价处于 60 日均线上方、120 日均线下方;
- 当周市场整体涨幅介于 -1% 至 +1%(低波动窗口)。
每增加一个筛选条件,模型就会在历史数据上表现得更"精准"——因为每个条件都进一步缩小了样本,直到留下来的样本恰好符合你想要的结论。这不是学习市场规律;这是记忆历史数据。
统计学家有一个经典说法:给我足够多的参数,我可以拟合任何一头大象。用四个参数,你可以描述大象的轮廓;用五个参数,你可以让它的鼻子摇晃。但这个大象只存在于你训练它的那批数据里,遇到新数据,它就消失了。
过拟合的另一层危险在于,它产生的模型在直觉上非常有说服力。一个具有五个筛选条件的信号,总能被包装出一套逻辑自洽的故事:换手率高反映活跃买盘,RSI 中性区间代表无超买超卖,MACD 收缩意味着趋势确认……每一条都有理论依据,整套叙事天衣无缝。只有样本外数据才能揭露它的真相。
六、反面教材:一个虚构信号的完整失败路径
以下是一个纯属虚构的教学案例,用于说明上述所有风险如何在现实中叠加。
信号构造(2017–2020 年回测期):某 A 股量化研究者在中小盘股中,发现了一个结合"放量滞涨 + 短期超卖 + 行业相对强度"的三因子信号。回测结果令人兴奋:2017 年至 2020 年间,信号触发 312 次,胜率 79%,平均持有 10 个交易日后平均收益 4.2%,最大单次亏损 -12%,年化夏普比率约为 1.4。每项指标都超过了通常被视为"可实用"的门槛。
样本外检验失败(2021 年):研究者使用 2017–2020 年数据训练,2021 年开始实时追踪(非实际资金)。2021 年前三个季度,信号触发 78 次,胜率骤降至 52%,平均收益 0.8%,而平均亏损升至 -9.3%。期望值由正转负。
归因分析揭示了三重叠加失效:
- 制度变迁(regime change):2021 年 A 股监管环境明显收紧,大量中小盘股估值体系重置,原先在"流动性宽松 + 注册制预期"环境下成立的超卖反弹逻辑失去土壤。信号在原环境中捕捉的,是一种历史上的市场倾向,而非普遍规律。
- 流动性约束(liquidity constraint):信号集中在中小盘股,平均每次触发时标的的日均成交量约为 5000 万元。当研究者估算即使以 50 万元规模实盘时,其买入和卖出行为对这类小盘股的影响绝不可忽视——实际成交价与理论触发价之间的滑点,大幅蚕食了历史上的微薄盈利空间。
- 过拟合暴露:回测期三年(2017–2020 年)恰好覆盖了 A 股市场的一次完整"熊牛转换"周期,筛选条件在无意间"学会了"这个特定历史路径的形态,而不是任何跨越周期的结构性逻辑。
这个案例不涉及任何真实标的或实际亏损。它的价值在于:它完整还原了高胜率信号从构建到失效的典型路径,缺少其中任何一步,反面教材都不完整。
七、真正的护城河:过程、性情、时间与信息的复利
如果高胜率不是护城河,那什么是?
护城河(moat)这个概念来自 Warren Buffett,描述的是一家企业抵御竞争侵蚀、维持超额利润的持久能力。将这个概念引入个人投资,意味着:什么样的优势是可以持续的,而不是在某个特定条件下昙花一现?
答案有四个维度:
一是过程优势(process edge)。护城河不是结果,而是产生结果的方法。投资者若能持续遵循一套纪律严明、基于第一原理的决策流程——比如系统性地区分"知道什么"与"不知道什么"、拒绝在能力圈之外行动、对每次决策保留书面记录供事后复盘——这套过程本身就是资产,因为大多数人无法长期执行它。过程的护城河在于,它是可以被强化和传承的,而市场条件是不断变化的。
二是性情优势(temperament edge)。Buffett 曾说,投资的成功与 IQ 的相关性,远不如与性情的相关性高。性情优势意味着:在市场极端恐慌时能够独立思考,在众人贪婪时能够保持克制,在长期枯燥的等待中不因无聊而制造交易。这不是与生俱来的性格特质,而是长期修炼、主动反思和持续自我纠错的结果。
三是时间视野优势(time horizon edge)。大量机构投资者受制于季度考核或年度业绩压力,无法在短期内承受哪怕有充分逻辑支撑的账面回撤。这为那些真正可以以 3 至 10 年为单位思考的个人投资者,留下了制度性的错误定价空间。这种优势不依赖任何信号,只依赖一个清醒的认知:你能忍受多久的"正确但痛苦"。
四是信息边际优势(information edge)。不是"拥有内幕信息",而是在某个细分领域,长期积累出的专业理解,使你能够在公开信息框架内更快、更准地解读信号。Peter Lynch 所说的"留意你身边的东西",本质上是把日常行业观察转化为信息边际——这种优势随时间加深,具有复利效应。
以上四种优势有一个共同特征:它们都难以被轻易复制,都需要时间积累,都与市场的具体形态解耦。它们不会因为市场制度改变或历史窗口结束而失效。这与"高胜率信号"形成鲜明对比——后者依附于特定历史条件,一旦条件改变,它就消失,就像露水在太阳下蒸发一样。
更多关于这种长视野决策框架的讨论,可参考本站 Howard Marks 二阶思维的深度解析。关于如何通过系统性信号评级构建更稳健的决策基础,也可参阅 信号评级系统的构建逻辑。
八、芒格的反转之问:什么会保证我亏钱?
芒格最著名的思维工具之一,是从数学家雅各比(Carl Jacobi)那里借来的"反转法"(inversion):面对任何问题,先问它的反面。
在 反转,永远反转:芒格最有力的心智模型 一文中,我曾详细讨论过这个方法。在此,不妨把它直接应用于高胜率信号的场景:
不要问"如何找到高胜率信号",而要问:"什么会保证我在信号上亏钱?"
答案几乎是立即显现的:
- 只看胜率,不看盈亏比——保证你在"小赚大亏"的结构中不自知地蒸发资本;
- 只看样本内,不做样本外测试——保证你的模型"学习"的是历史噪声而不是规律;
- 参数越多越好——保证过拟合,保证新数据让它看起来像一个陌生人;
- 忽视流动性和交易成本——保证实盘中所有理论盈利被摩擦消耗殆尽;
- 在市场制度变化时不更新模型——保证一个时代的工具在下一个时代成为累赘;
- 相信历史胜率等于未来胜率——保证以过去的地图穿越从未踏足的地形。
把这六件事全部做到,高胜率信号就会成为一个精巧的亏钱装置。
反转法的价值在于,它把注意力从"寻找完美答案"转向"避免必然错误"。前者的搜索空间是无限的;后者的清单是有限且可执行的。投资中最珍贵的进步,往往不是找到了新的赚钱方法,而是彻底杜绝了某一类已知的亏钱模式。
九、量化策略的正确使用姿势
在彻底否定高胜率信号的所有错误用法之后,有必要说清楚量化分析本身并无原罪。
量化方法在投资中的合理定位,是辅助决策,而非替代判断。它擅长处理人类大脑无法高效完成的任务:在数千只股票中批量筛选符合特定特征的候选标的、对历史规律做出统计描述、在情绪干扰下维持纪律执行。这些功能是真实的,也是有价值的。
但量化方法本质上是一面镜子:它只能反映历史,不能预见未来。当它被要求充当预言机——给出确定性的"此信号胜率 X%"——它就从工具变成了信仰,从辅助变成了依赖。
健康的量化使用框架,应当满足以下条件:
- 样本外表现(out-of-sample)优于随机,而非仅在训练期内表现优异;
- 对策略失效条件有清晰假设(例如:当市场流动性环境显著恶化时,模型可靠性可能下降);
- 仓位规模(position sizing)通过凯利公式或类似框架约束,而非由信心驱动;
- 交易成本和流动性在模型中被显式计算,而非后置处理;
- 定期对策略假设进行再验证,尤其在市场制度发生变化之后。
以上每一条,都不是量化分析的额外附加要求,而是它能够发挥正常功能的前提条件。
常见问题
样本内胜率很高,是否可以说明策略至少在历史上有效?
样本内胜率高,只能说明这个参数组合对历史数据有较好的拟合能力,并不能证明策略对于历史的捕捉来自真实的市场规律而非噪声记忆。区分二者的唯一可靠方式,是在严格分隔的样本外数据上进行独立验证——且验证期要足够长,覆盖至少一个完整的市场周期(约 3 至 5 年)。即便如此,仍需注意模型部署后的环境是否与历史数据所代表的制度背景保持一致。样本内胜率是假设的起点,不是结论。
如果一个策略在实盘中短期胜率仍然很高,是否说明它有效?
短期实盘胜率高,在统计学上面临严重的小样本问题。一个随机策略在 20 次交易中,完全有可能出现 14 次甚至 16 次正确(胜率 70%–80%),这在 95% 置信区间内仍属正常随机波动。要对一个策略的真实有效性下结论,通常需要数百次独立且无相关性的交易记录,而这在中等持仓期(10 至 60 个交易日)的策略上,往往需要数年才能积累。此外,即便样本数量足够,也仍需结合期望值、制度稳定性和流动性约束进行综合评估,而不能单纯依赖胜率数字。
小结:护城河不在统计表格里
投资者对高胜率的执念,本质上是对"确定性"的渴望。在一个充满不确定性的市场里,一个显示"82% 胜率"的数字,提供了一种短暂的安慰:这里有一块稳固的地基。
但市场的本质是概率分布,不是确定的重复。所有回测结果都是对已发生历史的描述,而市场明天的样子,永远包含历史无法完全预见的成分。
真正意义上的护城河,是那些在市场改变时仍能持续运作的东西:对自身局限的诚实认知、对决策过程的长期纪律、对时间视野的充分利用,以及对已知错误模式的系统性回避。这些能力不显示在任何回测表格里,也不产生任何可以截图分享的"胜率数字"。但它们是真实的,而且,它们复利。
以芒格最喜欢引用的方式作结:
"我只想知道我会在哪里死——这样我就永远不会去那里。"
— 查理·芒格
对于寻找高胜率信号的投资者来说,这句话的反转版本或许是:先把那些注定失败的路列出来,然后永远不走。
本文所有回测案例及数字均为假设性教学情境,不涉及任何真实标的的买卖建议或操作指导。本文作者不具有投资顾问资格,任何投资决策均应基于读者自身判断与研究。
延伸阅读:如果您对本文讨论的方法论感兴趣,欢迎关注公众号「柔和谦卑 履责 求知」(sustine_et_abstine),持续获取更多基于第一原理的投资与思维方法论内容。